My searches in the forum have not come up with an answer for this problem. If I’ve missed something, I would appreciate a link to an existing discussion.
I’m using version 3.3.1 in a BSD environment. I’m not using cron, I just trigger queue processing via the Web UI and wait for it to finish (but it never does).
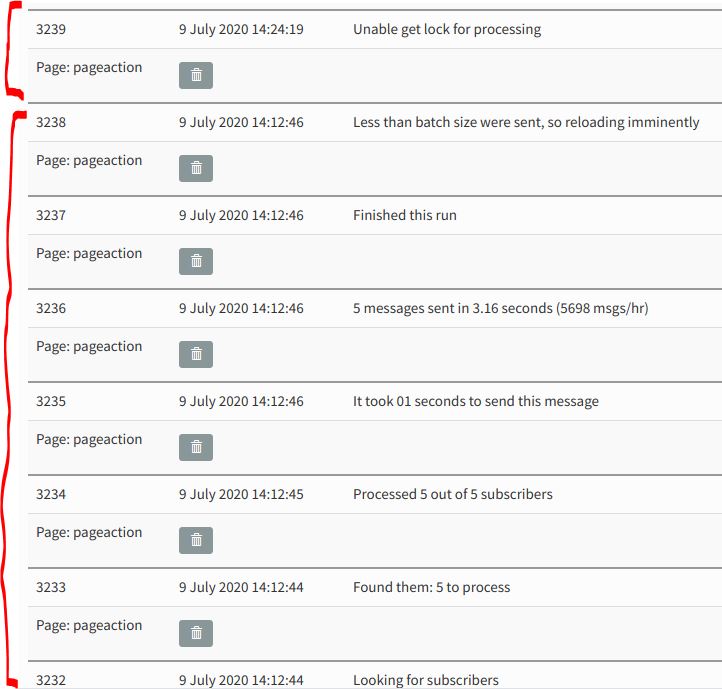
When a campaign is done (i.e., everything in the queue is successfully), the updating log of actions in the queue processing window shows the “nothing more to do” message but the process never stops, even if I leave that browser tab open for hours. I can manually “cancel” the (already-finished) process using the button provided for that purpose, but this typically hangs my phpList session. Whether I manually stop it or not, the lock in the database remains, so every time I want to send a campaign, I have to open the database and make sure I manually removed the lock before or do so at that time.
Am I misunderstanding something, or is this a bug? It seems to me that when the queue is empty and everything is done, processing should end, the lock should be removed, and I should be able to continue using phpList (i.e., navigating to other pages) without opening a new browser window.
The attached screen clip shows an instance of what I’m talking about. I sent a campaign to my test list (to test something unrelated to this issue) and now I must – as always – modify the database directly to remove the lock. As can be seen in this clip, there is “Nothing to do” but there is still the “Stop processing” button. I always end up “stopping” the already-complete process, but the lock in the “sendprocess” table remains.
I wish I’d had a chance to test this with the current Release Candidate but I just haven’t had time.
I had some thin hope that 3.3.2 might (accidentally?) fix this, but the problem remains.
I assume this problem prevents me from fully automating things because I can’t set up a cron job as long as I have to manually delete a record from the phplist_sendprocess table after every send action. As I understand phpList and this problem, the first cron job would run fine (instead of me clicking the “cancel” button after everything is finished, I think the cron process would time out(?)), but after that nothing would work until I manually deleted that record. Rinse and repeat.
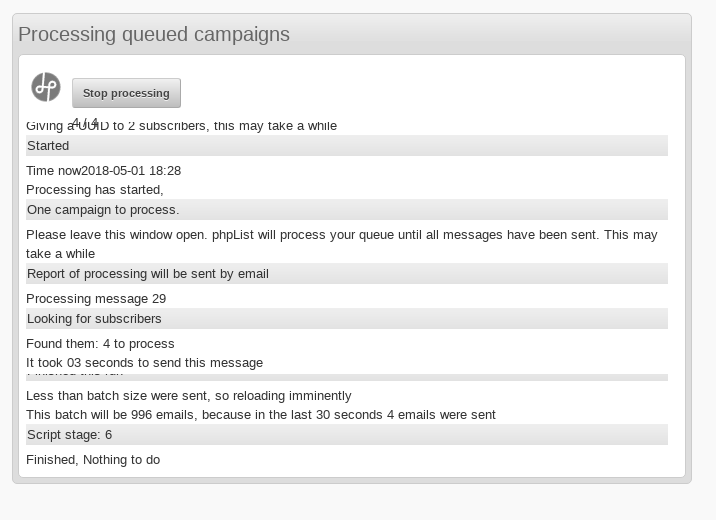
I don’t see anything in the log that shows any error happened. The following screen clip shows what I see after sending a test campaign, waiting a short while, and then clicking the button to manually cancel the (already-finished) processing.
I spent some time (over an hour) trying to trace through the code and find a way to debug this but there’s no way I can jump into that in a reasonable amount of time given the circumstances – my unfamiliarity with the code, the state of the code (lots of cruft from what I could see), my need to be productive on other things, etc.
Well, apparently this is not true, because command line and in-browser queue processing work differently. When I was perusing the code I saw something that hinted this might be the case, and today I finally took the time to try it. Sure enough, the send process ends cleanly and the lock is removed.
So while the browser interface for queue processing is apparently broken (at least in my production environment), I actually can set up a cron job to process the queue. I prefer processing the queue manually when I want the message to start sending, but if it keeps me from constantly using phpMyAdmin to delete a leftover record, I guess I’ll switch to cron processing. Not sure how frequently I’ll have it run, though. Hmm.
Ha… nope. When the command line process processes the queue and there’s nothing to send, the lock is left behind, making future queue processing abort immediately.
I’m having a conversation with myself here, but I know at least one other person ran into this, per that earlier thread that also did not get resolved. This is frustrating in the truest sense of the word. Sending campaigns should not involve accessing the database manually every single time.
I’ve been putting up with this problem since early 2018 and today, for the first time, it worked as expected. When a campaign finished sending, I got “All done” instead of it just being stuck on “Finished, nothing to do” – and, most important, I was able to send another campaign right away without updating the database manually to clear the zombie send process.
However… I don’t know why it started working. Two things of note since I last had to manually delete the zombie (a couple weeks ago)…
I rebuilt the DB indexes
I updated all of my plugins, all of which were woefully outdated
Of the two, I’m guessing the first one is the one that made the difference. It seems more likely…? I should also note that I’m fairly sure this was not fixed by my recent phpList update, because (to the best of my memory) I tested the problem immediately after that upgrade and it was still there.
Anyway, I’m happy that things are finally working as expected after a campaign finishes, literally for the first time since I started using phpList. Very glad to have that database-editing obstacle behind me at last!
This is significantly enabling, as long as it lasts. I’m admittedly nervous that it’s going to fail again.
With that lock being deleted correctly after processing, I can now use cron to process the queue, which means I can finally do an autoresponder/automated onboarding sequence, instead of responding manually.
This could be really great… or it could be tragic if it starts failing again. I wish I knew why it suddenly started working, so I could have that tool in my toolbox if the problem does crop up again. In thinking about the DB index rebuilding, I’m less confident that was relevant, because I think I’ve done that before without any apparent impact. (I know, if I was strict about my admin processes I wouldn’t have to rely on memory…)
That makes me wonder if something in one of the plugins I updated was interfering before, and now it has been fixed (whether that was an intended fix or a side-effect). The plugins I updated, which were years out of date now but were current when this problem started, were:
AmazonSes
CKEditorPlugin
CommonPlugin
SegmentPlugin
SubscribersPlugin
ViewBrowserPlugin
Of those, AmazonSes seems most likely to be relevant since it’s involved in sending. @duncanc, any thoughts on whether an older version of that plugin might have left the sending process locked (i.e., not deleting the record from phplist_sendprocess)? Or maybe CommonPlugin… although I don’t know what all that does, the name just suggests the potential to have wide-ranging impacts.
I have repeatedly thought about abandoning phpList over this problem. Now that it’s working right, y’all aren’t going to get rid of me anytime soon.
@Crenel84 Unless there are errors reported in the event log then I don’t think that the plugins are causing the problem.
But using a cron job is going to be more reliable than processing through the browser because it gives more control.
I suggest using batch processing so that phplist sends a fixed number of emails then exits. So long as the execution time is less than the period between cron job initiations then it should run smoothly. It also will give clearer errors if anything goes wrong (redirect standard output and standard error to a log file).
I never noticed any errors, the lock was just never released. (I’ll see if the log data goes back far enough and check again.) Subsequent sending would fail if I didn’t manually clear the lock after every send. This prevented me from using cron before, as it would’ve only sent the first batch and failed after that.
I definitely want to use cron batch processing going forward. It would be easier to trust what I set up to continue working if I understood why this problem happened and how I (inadvertently) resolved it. If I build up an onboarding sequence based on cron processing of the queue, I’ll have to shelve that if I have to go back to manually clearing the lock.
@Crenel84 Have you tested using a cron job? Processing the queue in the browser works in a different, more complicated way than from a command line, so the problem may well not occur.
As I recall (this was a couple years ago) I tested it interactively on the command line to see if running via cron would work, using a test message to just a couple addresses, and it still left the lock in place. I assumed the same would be true if the command line process was triggered via cron instead of interactively, so I just went back to doing it in the browser.
@Crenel84 Looking at the code I can’t see why the row in sendprocess table should not be removed. It seems to work fine for all the phplist installations that I support.
You could try enableing php error reporting in the shutdown function to see whether that shows anything
in file admin/actions/processqueue.php
line 247 is function my_shutdown()
If this comes up again, I’ll give that a try. Don’t want to mess with it while it’s working.
I looked back at the log from when I last saw this problem. On July 9 I upgraded phpList and sent a test message to a few addresses to make sure nothing had failed catastrophically. That went fine, so I tried another message without touching the database, but the lock was still there so it failed. I’ll attach a screen clipping of the log, the single log entry at the top is from the failed campaign:
They’re not defined right now, so (if I understand correctly) currently using the defaults of 0 and 3600. I don’t remember if I defined them specifically when I tested processing on the command line in 2018, or (if so) what settings I tried. I was focused on the locking record and my tests always go to just a few addresses, so assuming I didn’t define unusually low values, those few emails should have gone out and then the lock should have been cleared (again, if I understand correctly).

 and thank you for sharing your findings!
and thank you for sharing your findings!